BitBucket is a popular source control management system from Atlassian. My side project, PostRope, uses BitBucket cloud as its source code management (SCM) tool, allowing me to share code with other developers on the team and serve as a cloud based backup of the code.
BitBucket pipelines are a feature of BitBucket that allows the creation of a continuous delivery (CD) pipeline in a BitBucket repository. It allows the specification of steps to be performed in response to commits into the repository using a specified docker image. Now rather than just being an SCM tool for PostRope, BitBucket now lets me implement a continuous delivery pipeline with very little effort. And because the pipeline runs in a docker instance on demand, now new infrastructure (aside from the docker image) need be established.
The advantage of this approach is that it means everything required to run a CD pipeline is maintained in the repository. A docker container is spun up by BitBucket, the repository is cloned in to it, and the specified steps are executed. The steps are defined in a yaml file and multiple pipelines can be specified with different steps. The pipeline selected is chosen using a set of rules matching commits to branches or tagged commits.
BitBucket pipelines are only available for BitBucket Cloud. In server environments Bamboo will still be used. My personal experience has been that BitBucket pipelines are an easy way to quickly setup a CI/CD pipeline for my project. The following describes how I have set up a CD pipeline for a web application I work on in my spare time called PostRope.
CD Pipeline in PostRope
PostRope is a Scala application that uses the lift framework. It uses a mysql database and runs on tomcat. It has two environments in AWS. These are a staging environment where the team test out new features, and a production environment used by our live users. The AWS environments are elastic beanstalk environments so they’re easy to scale and redeploy or rebuild as required.
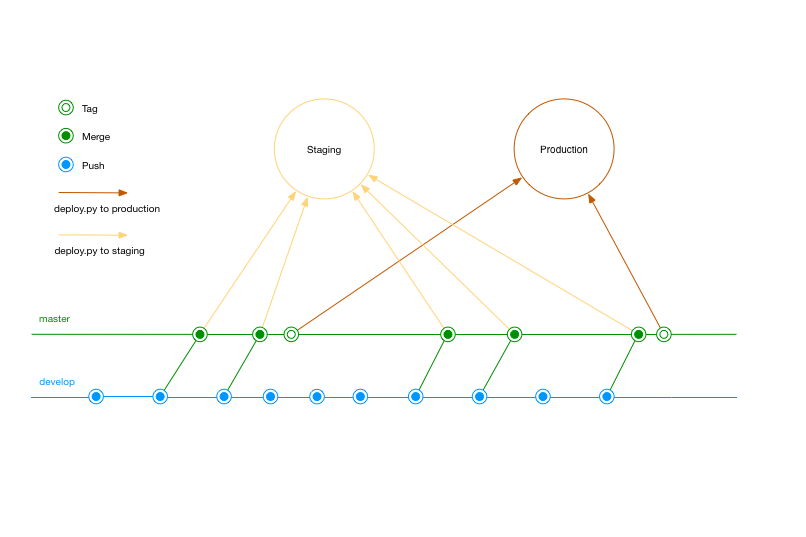
In BitBucket there are two branches, master and develop. The develop branch is used by developers to share code. The master branch is used to generate the deployable application. We apply continuous integration (CI) to both branches. We only apply continuous deployment (CD) to master. The target environment for deployment depends on whether the commit to master is tagged. Regular commits are deployed to staging and tagged commits are deployed to production.
Our CD pipeline consists of two phases, Integration and Deployment.
Integration
Both the master and the develop branch are under continuous integration (CI). Each time a commit is made to either branch, the integration tests are run to ensure the functionality of the site has not been broken. The full unit tests and functional tests are not run as part of the integration to keep execution time down. It is expected that developers run these tests before committing changes.
If an integration test fails, the developers receive an email notification. During CI in develop we don’t mind receiving notifications that integration is failing on areas that are being worked on. We do mind if areas not being worked on start to fail, as this is an indication of an unintended side effect of a change that has been made.
The docker instance spins up, compiles and packages the code, runs the integration tests and emails the results, then shuts itself down. At the end of integration, we have a deployable artifact and the results of integration tests.
Deployment
Deployment is part of the pipeline whenever a commit is made to master or tag is created in master. Our pipeline is configured to trigger a build and deploy from master to staging every time a commit is made into master. Integration has already run. The deploy script is invoked after integration has run. If the integration tests have failed, then deployment is abandoned. If integration testing of the deployable artefact has passed, then this artifact is then copied up to S3 and deployed to the AWS beanstalk instance of our staging environment.
The deploy.py that handles the copy of the artefact and the restart of the instance uses the BitBucket default variable BITBUCKET_TAG to determine what action to take. If the tag variable exists and matches the pattern release-* then the deployment is to production. If the variable does not exist then the artefact is deployed to staging. This test is sufficient because we know deploy.py is only invoked from commits into mater as per our pipeline definitions in the yaml file. The AWS specific values required for deployment, such as AWS keys and application and environment names are stored as repository environment variables and the appropriate ones are loaded based on the BITBUCKET_TAG variable.
An alternative approach here would have been to have separate scripts to deploy to production and to deploy to staging. If the logic for the cases were different this would be my preferred option – however at this time the logic of the two scripts is identical with just some variable values changing between production and staging. Having different scripts is certainly an option to consider if there are functional differences in deployment.
Pipeline
The pipeline for PostRope is defined in a simple text file.
# PostRope CI/CD pipelines
# Check our guides at https://confluence.atlassian.com/x/VYk8Lw for more examples.
# Only use spaces to indent your .yml configuration.
# -----
# You can specify a custom docker image from Docker Hub as your build environment.
# image: docker-image:tag
image:
name: postrope/sbt-image # name changed to protect the innocent
pipelines:
branches:
develop:
- step:
script:
- sh integration.sh
master:
- step:
script:
- sh integration.sh
- python deploy.py
tags:
release-*:
- step:
script:
- sh integration.sh
- python deploy.py
The pipeline workflow is defined in YAML file in the repositories root directory. There are three rules for PostRope pipelines. The first rule triggers whenever a commit is made to the develop branch, and cause the integration script to be run. The second rule triggers whenever a commit is made to the master branch, which causes integration to run and then the deploy script to run. The third triggers whenever a tag is created that matches the glob pattern release-*. For the master branch pipeline and the tag pipeline, the behaviour of the script is varied by the existence of the tag variable as part of the bit bucket environment.
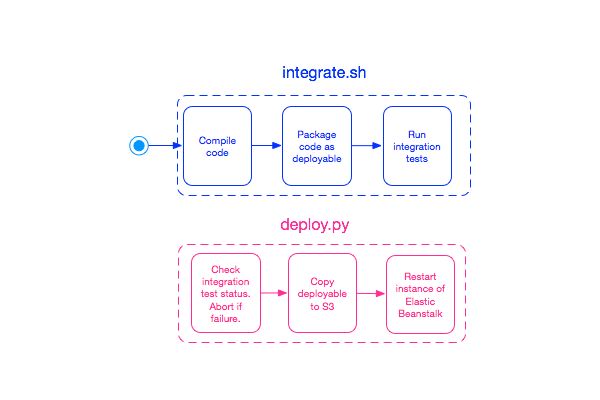
The script files integration.sh and deploy.py are just source files in the git repository and are maintained as part of the project. Similarly the yaml file defining the pipelines is also part of the repository. This means developers can easily maintain the CD pipeline without requiring access to a separate system.
Summary
BitBucket pipelines is a simple way to add a CD pipeline to a codebase that uses BitBucket cloud for source code management. It is easy to specify pipelines using a yaml file and scripts that are managed as part of the application source.
One thing to be aware of is that when the docker instance is spun up for the build, there will be costs incurred for the build. That is why I only use pipelines for master and develop – other branches do not use the pipeline to keep costs down. Currently pipelines are free to experiment with but will eventually incur a cost associated with the docker instance used to run the pipeline.
The cost is pretty minor compared to the benefits of having code flow directly into our environments. For BitBucket cloud instances, pipelines are easy to setup and use, and a cheap way to deliver code to production.
References
https://devops.com/continuous-delivery-pipeline/
https://www.martinfowler.com/articles/continuousIntegration.html
https://www.agilealliance.org/glossary/continuous-deployment/
https://confluence.atlassian.com/bitbucket/configure-bitbucket-pipelines-yml-792298910.html
https://confluence.atlassian.com/bamboocloud/bamboo-cloud-eol-827125716.html